Build, train, deploy AI. Finally at the right price
Run serious AI workloads on latest GPUs with OpenAI-compatible APIs, fixed outcome-based pricing, and full GCC data residency. Any model. Full control. No more bill-shock.
FASTER SPEEDS

Sub‑50 ms latency
across UAE, India, MENA, and Eastern Europe.
PRICING BY TASK

≥80% cheaper
with accurate pricing per task, not tokens.
THOUSANDS OF MODELS

Open-weight model library
Hugging Face and OpenAI API compatible.
FAST DEPLOYMENT
Scope, build, deploy in 5 minutes.
FASTER SPEEDS
Sub‑50 ms latency
across UAE, India, MENA, and Eastern Europe.
PRICING BY TASK
≥80% cheaper
with accurate pricing per task, not tokens.
THOUSANDS OF MODELS
Open-weight model library
Hugging Face and OpenAI API compatible.
FAST DEPLOYMENT
Scope, build, deploy in 5 minutes.
Build, train and deploy AI.
From our data centers in the UAE
Up to 80% cheaper and 2x faster than US hyperscalers
Low latency for MENA, Eastern Europe, India and SE Asia inference in H100 GPUs UAE data centres.
Task-based pricing with fixed, predictable prices
Get faster
AI inference
Hire sovereign UAE compute with up to 80% lower AI infrastructure costs and multiple benefits
Hire sovereign UAE compute with up to 80% lower AI infrastructure costs and multiple benefits
faster Inference
2X
faster training pace
2X
cheaper
up to
80%
network compression
117X
Full-service success stories
"We sincerely appreciate the exceptional support provided by Hyperfusion. The team’s flexibility, agility, and commitment enabled us to meet a very challenging timeline and deliver the scope successfully. Their responsiveness and professionalism reflect the strength of our partnership, and we look forward to collaborating on future projects."
Alex Turner
Senior Business Manager -Enterprise Business (MEA)
XLLENZA Technologies
"Hyperfusion has been a lifesaver, providing state-of-the-art compute at very competitive prices within the UAE. The support team is highly responsive and resolves issues in real time. We have been using their services since early last year and hope to continue doing so."
Hood Khizer
Technical Director | Cognitive Services Architect
AHOY
"The GPU environment was smooth and reliable, and the overall service quality met our expectations.
The support team was quick, responsive, and highly cooperative throughout our engagement. We appreciated the timely assistance, clear communication, and technical guidance when needed. The onboarding and provisioning process was handled efficiently, making our testing and processing much easier."
Shan Ali Syed
Manager IT & Security Services
Rapidev Group of Companies
How it works
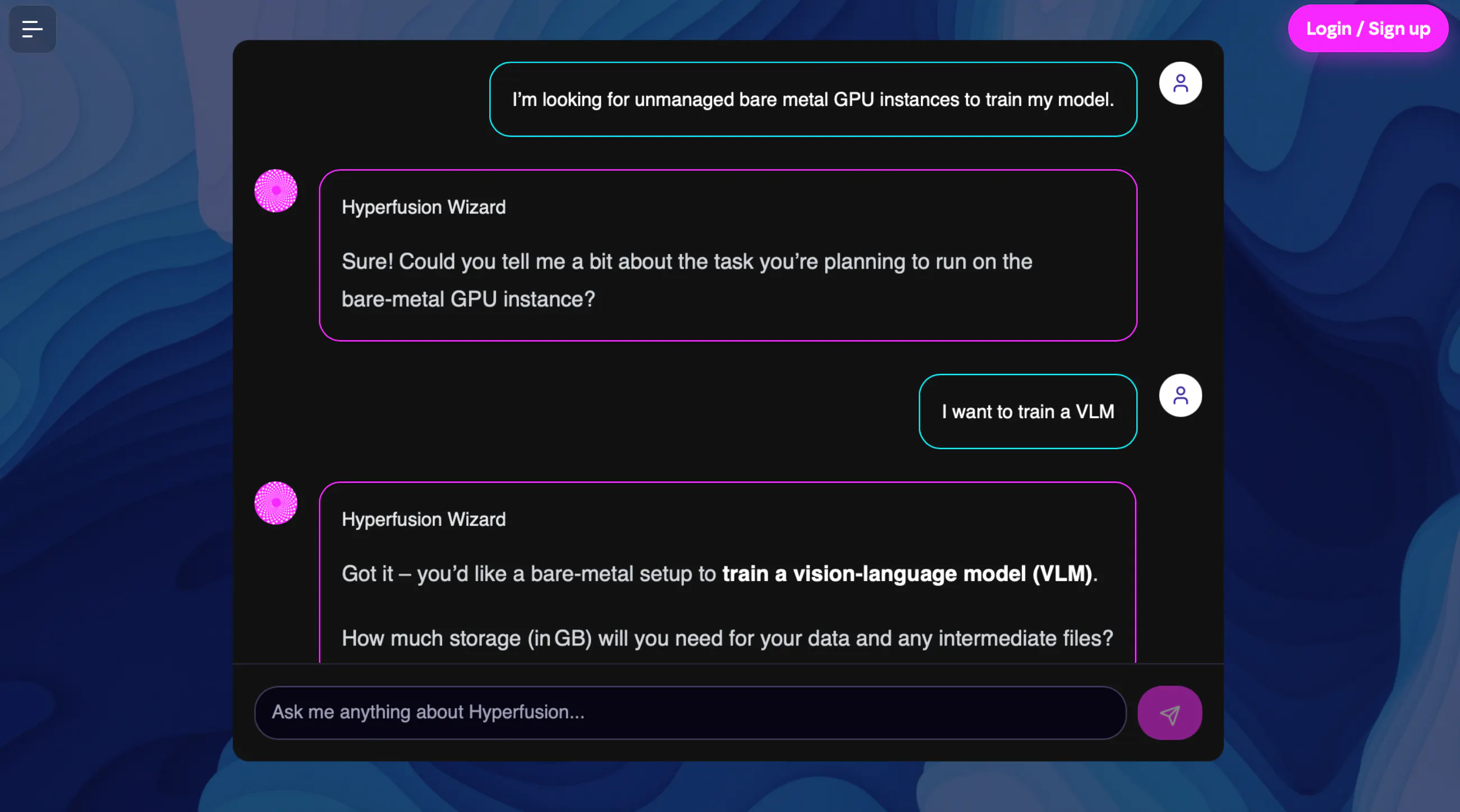
Step 1
DESCRIBE
YOUR AI TASK
Eg. “I need high-volume text-to-text summarisation for long documents.”
“I need a multimodal model taking image and text input, returning detailed responses.”
Step 2
TRAIN
& FINE TUNE
Open source inference for language, vision and speech on shared or private infrastructure. Fine-tuning from fully managed to self-operated on dedicated GPUs. Evaluations and experimentation at scale.
Step 3
EASY
DEPLOYMENT
Your config turns into a production-ready system, deployable in minutes.
Step 1
DESCRIBE
YOUR AI TASK
Eg. “I need high-volume text-to-text summarisation for long documents.”
“I need a multimodal model taking image and text input, returning detailed responses.”
Step 2
TRAIN
& FINE TUNE
Open source inference for language, vision and speech on shared or private infrastructure. Fine-tuning from fully managed to self-operated on dedicated GPUs. Evaluations and experimentation at scale.
Step 3
EASY
DEPLOYMENT
Your config turns into a production-ready system, deployable in minutes.
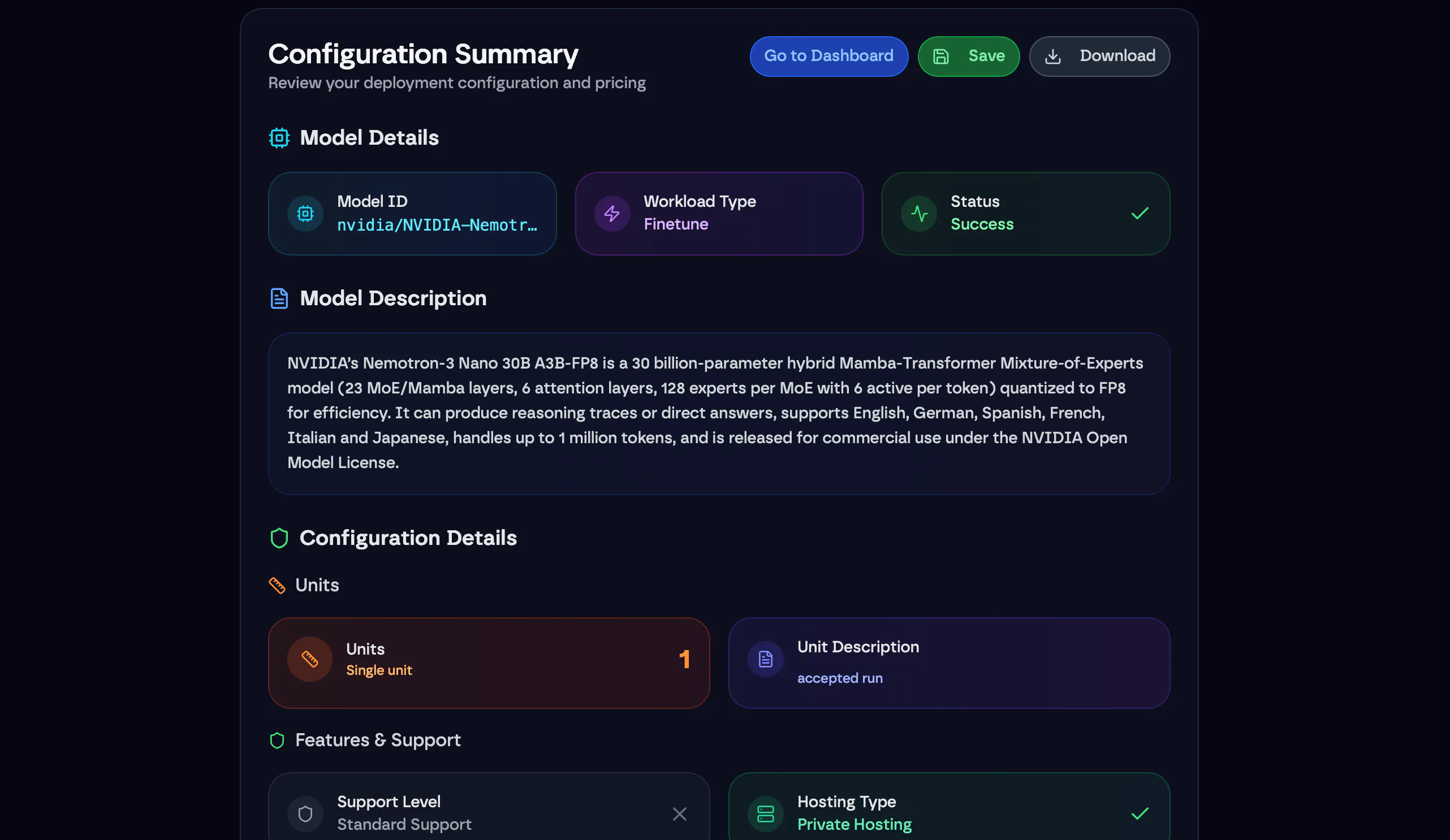
Everything you need to build, run, and scale AI
WIZARD UI
The simplest way to specify, price, and deploy AI; built for everyone.
GPU COMPUTE
High-performance infrastructure to power demanding AI workloads.
IT OPERATIONS
Our team ensures seamless management and continuous optimization of our clusters.
IT INTEGRATIONS
Our expertise allows us to seamlessly connect with your existing infrastructure and solutions, delivering a tailored experience that meets your unique needs.
AI CONSULTANCY
We help businesses navigate the complexities of AI adoption, from strategy through to implementation.
WIZARD UI
The simplest way to specify, price, and deploy AI; built for everyone.
GPU COMPUTE
High-performance infrastructure to power demanding AI workloads.
IT OPERATIONS
Our team ensures seamless management and continuous optimization of our clusters.
IT INTEGRATIONS
Our expertise allows us to seamlessly connect with your existing infrastructure and solutions, delivering a tailored experience that meets your unique needs.
AI CONSULTANCY
We help businesses navigate the complexities of AI adoption, from strategy through to implementation.

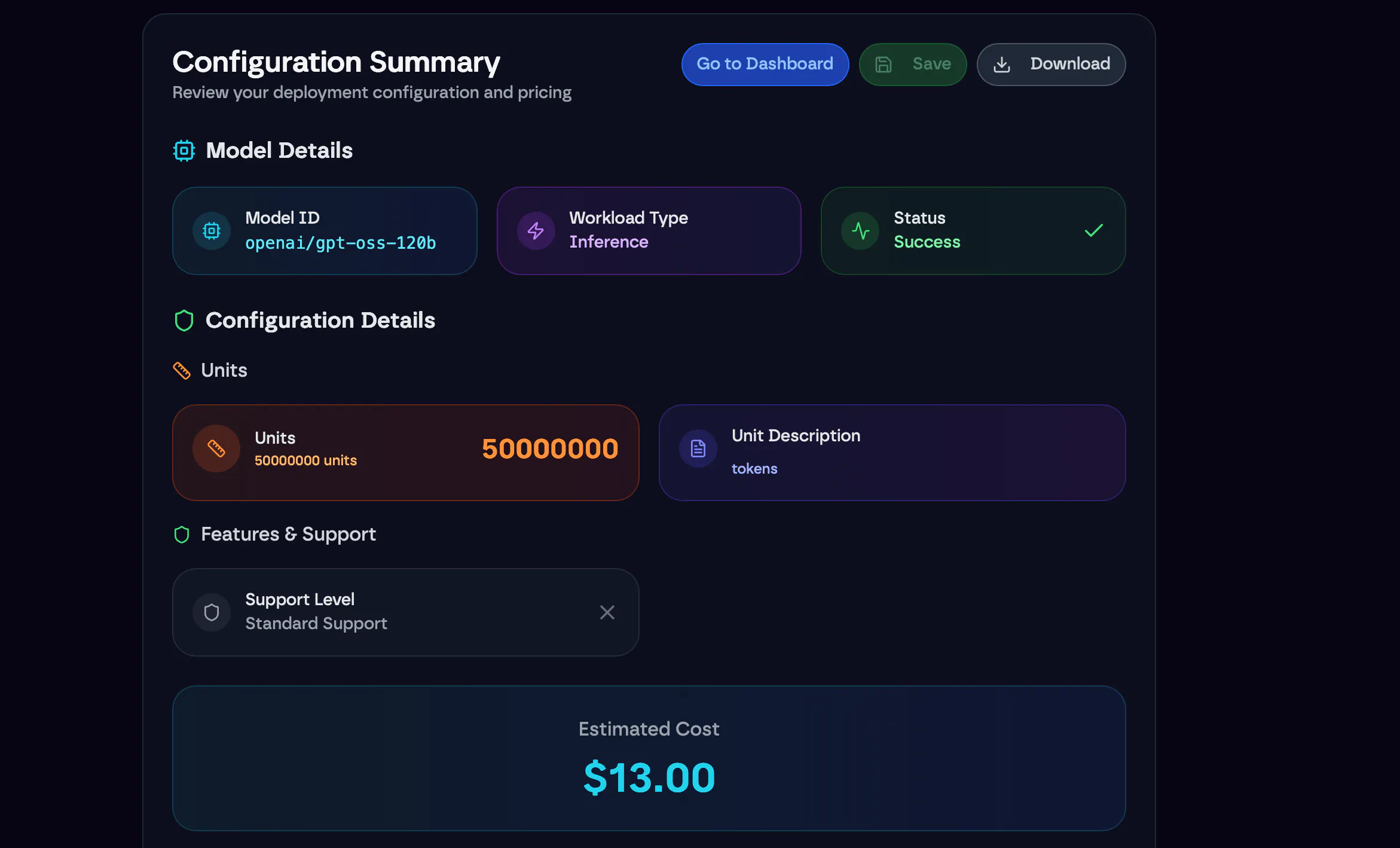
Scope your task and start for free
Describe your project
& get a fixed price

Startups & Dev Teams
Ship AI features fast
Build fast
Launch chat, voice, and video features using familiar APIs.
Low latency
Local GPUs mean MEA and Indian users enjoy instant AI experiences.
Predictable costs
Scale with predictable costs. No US hyperscaler bill-shock.
Small & Medium Businesses
AI without complexity
Full service support
Introduce AI-powered support, search, and automation, no ML hires required.
Local languages
Serve customers with fast, language-aware AI tuned for local markets.
Scale easily
Build and scale features with full IT support.
ML Researchers
Experiment faster, iterate cheaper
Train
Train and fine-tune thousands of open-weight models without premium pricing.
Local data
Evaluate models for Arabic and Indic languages on regional infrastructure.
Immediate access
Run inference-heavy workloads without queuing for global GPU capacity.
Global Product Teams
Consistent AI performance, everywhere
Local
Serve local markets from local data centers.
Predictable costs
Cut inference costs with fixed, task-based pricing.
Simpler
A single, unified platform for all AI use cases.
Enterprise & Government
Deploy AI with compliance and confidence
Sovereign data
Run AI workloads with guaranteed data residency and regional compliance.
Local languages
Support citizen-facing and internal applications with local language support.
Local MENA partner
Partner with a provider aligned to sovereign AI and regulatory requirements.
Channel & Solution Partners
Deliver AI without owning infrastructure
Full service offer
AI-powered solutions without building or managing teams or GPU stacks.
New revenue
Create recurring revenue through integration, delivery, and managed services.
Compliant
Meet regional compliance and latency needs with a partner-first platform.
Market Intel
Get GPU market and model usage insights to your inbox.